NPAQ
Quantitative Verification for BNNs

We propose and formalize quantitative verification for neural networks in our CCS19 paper. In quantitative verification, we are interested in how often a certain property holds true for a neural network, rather than the classic notion of verification where we want to check if the property always holds. Our framework is the first to provide PAC-style soundness guarantees, in that its quantitative estimates are within a controllable and bounded error from the true count. We instantiate our algorithmic framework by building a prototype tool called NPAQ (Neural Property Approximate Quantifier) that enables checking rich properties over binarized neural networks.
Our prototype’s code and usage instructions are available on NPAQ’s Github page.
We show how emerging security analyses can utilize our framework in 3 applications: quantifying robustness to adversarial inputs, efficacy of trojan attacks, and fairness/bias of given neural networks.
An extended version of the CCS19 presentation is available here.
Here, we give an overview of our approach and implementation, along with explanations for our benchmarks.
NPAQ: Neural Property Approximate Quantifier
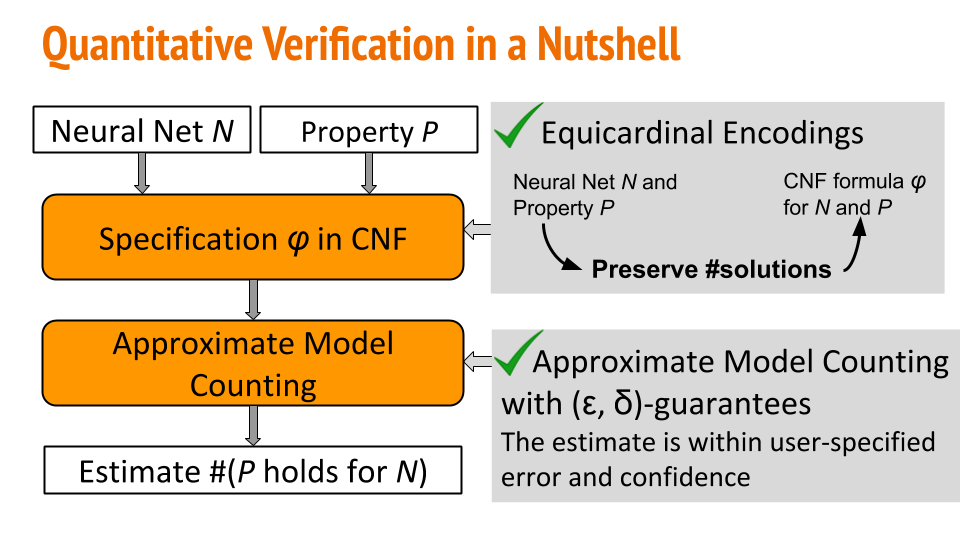
NPAQ takes as input a BNN and one of the properties to quantify: robustness, fairness and trojan attack success. NPAQ, then, outputs an estimate of how often the property is satisfied for the given neural network. The property is defined as a simple constraint over inputs and outputs.
In a nutshell, NPAQ encodes the BNN and the property to a specification as a Boolean logical formula in conjunctive normal form. In the encoding we show that we can preserve the number of solutions from the neural network space of solutions to the Boolean logical formula’s solution space. The last step is to estimate the number of solutions with PAC-style guarantees using an approximate model counter.
At the moment, we only support PyTorch models and we have pre-trained models but the user can train models with different architectures in the train mode of NPAQ.
Our prototype’s code and usage instructions are available on NPAQ’s Github page.
Background
Binarized neural networks (BNNs) are a type of feedforward neural network that are used in resource-constrained environments. After training, BNNs have weights can be either -1 or 1 and have a sign activation function. BNNs are structured in blocks where each block is an affine transformation, followed by a batch normalization and the activation function. The last layer is an affine transformation, followed by an argmax.
Given a test input for which the neural network outputs the correct class or label, researchers have shown that we can construct adversarial examples. These are inputs that are imperceptibly indistinshinguable from the test input but for which the neural network outputs a wrong label. We say a neural net is (locally) robust if there are no adversarial examples for a given test input.
Benchmarks
We provide the benchmarks used in our evaluation of NPAQ here. The benchmarks include the binarized neural networks used to evaluate NPAQ (see BNN Models), the processed UCI Adult dataset one of the datasets used for training (see Datasets for Training BNN), the input constraints for fairness (see Extra Constraints for Fairness), the resulting formulas in DIMACS (see CNF Formulas) and the concrete MNIST test images for the robustness property (see Robustness Images).
BNN Models
These are saved PyTorch binarized neural networks (format file is .pt) in the archive npaq-ccs-bnn_models.tar.gz.
We trained BNNs with the following architectures:
- ARCH1 (
1blk_100): 1 block 100 neurons - ARCH2 (
2blk_50_20): 2 blocks 50, 20 neurons - ARCH3 (
2blk_100_50): 2 blocks, 100, 50 neurons - ARCH4 (
3blk_200_100): 3 blocks, 200, 100, 100 neuorns
There are models trained on MNIST and models trained on the UCI Adult dataset. The MNIST dataset has been resized to 10x10 and the UCI Adult dataset has 66 binarized input features. We use the models trained on MNIST for quantifying local robustness, comparing the robustness of plain BNNs and hardened BNNs, along with quantifying the success of trojaning attacks. The UCI Adult dataset is used for quantifying fairness in our evaluation.
MNIST. For the models trained on MNIST, the npaq-ccs-bnn_models/mnist folder contains 4 .pt files corresponding to ARCH1 to ARCH4. The naming convention of the files is to have $dataset followed by the input size. For example, mnist-100-bnn_1blk_100.pt corresponds ARCH1 trained on a resized MNIST of 10x10.
MNIST Adversarial. We employ two techniques to adversarially train the MNIST models from npaq-ccs-bnn_models/mnist. The models obtained are in npaq-ccs-bnn_models/adv_3_mnist and npaq-ccs-bnn_models/adv_mnist. For each of these, we snapshot them at epoch 1 and epoch 5.
MNIST Trojan. We perform trojaning attacks on the MNIST models with trojan labels as 0, 1, 4, 5 and 9. For example, the trojaned models for label 0 are in folder the npaq-ccs-bnn_models/trojan_mnist_1-target_0. For each label, during the training of the models with the poisoned dataset containing the trojan, we snapshot the models at epochs 1, 10 and 30. Please note that we follow the following naming convention $dataset-$target-$input_size-$arch-$epoch. For example:
-
trojan_mnist_1-target_0-100-bnn_1blk_100-epoch_10.pt- BNN with 1 block, 100 neurons, trained on MNIST to insert a trojan in the training such that when that trojan is present in the input the model classifies it as target class 0 (target_0) and traines for 10 epochsepoch_10.
UCI Adult. The models used for the fairness application are in the folder npaq-ccs-bnn_models/uci_adult, corresponding to ARCH1 to ARCH4.
Datasets for Training BNN
In the benchmarks, we have models that are trained on two commonly used datasets, MNIST and UCI Adult.
MNIST. Standard MNIST dataset, use ‘–resize=S,S’ option to resize the image to SxS dimension
UCI Adult. This datasets predicts the annual income for an individual, given a set of features such as gender, age, whether the person is married, single or divorced. For more information, please refer to the UCI Adult dataset. We preprocess these features and binarize them.
Preprocessing step:
- removing incomplete samples
- removing duplicated samples
- removing conflicted sample
Robustness Images
For quantifying local robustness, we use 30 concrete images sampled from the MNIST test set. We saved these in concrete_inputs.tar.gz as text files. The images are flatten to 1D vectors, leading to 100 inputs. Normally, the images are binarized with values of -1 or 1 but here we use boolean values of 0 and 1, so an entry of -1 in the image corresponds to 0 for the flattened representation and an entry of 1 corresponds to 1.
You can find the concrete test images we used here.
CNF Formulas
The formulas are in DIMACS format with the projection at the beginning of the file. The header p inf declare the number of variables and the number of clauses which is specific to DIMACS. The header c ind specifies the projection variables. The formulas are available here – you can also go to the main folder and find them in the npaq-ccs-formulas_card.tar.gz.
p inf #vars #clauses
c ind v1 v2 .. vn
Extra Constraints for Fairness
In our encoding of the UCI Adult dataset features, we represent each feature using a binary vector (not one-hot encoding). Hence, we add extra constraints to exclude the features that are outside of the permitted values. The constraints in CNF format are available here.
| No | Feature | Vars | #Vars | Additional constraints |
| 5 | marital | 20-22 | 3 | 4 * x21+2 * x22 + x23 <= 6 |
| - | ------------ | ----- | ----- | --------------------------------------- |
| 6 | occupation | 23-26 | 4 | 8 * x27 + 4 * x26 + 2 * x25 + x24 <= 14 |
| 7 | relationship | 27-29 | 3 | 4 * x30 + 2 * x29 + x28 <= 5 |
| 8 | race | 30-32 | 3 | 4 * x33 + 2 * x32 + x31 <= 4 |